NCAA Basketball Team Clustering and Analysis
03/2024-05/2023
Inspiration
This project was inspired by my deep love for basketball and data science. Having played basketball competitively until college and continuing with intramural leagues, I have always been fascinated by the strategy behind team performance. With my brother playing Division I basketball, I found it particularly interesting to analyze how different college teams perform. This project allowed me to merge my passion for basketball with data science methods to discover insights that could help teams, analysts, and fans better understand the game.
Objectives
- Cluster Division I NCAA men's basketball teams based on their performance metrics
- Use Principal Component Analysis (PCA) to reduce the datasets dimensionality
- Identify key features that differentiate the clusters of teams
- Provide insights for teams to improve their strategies and performance
Key Features
- Comprehensive dataset from 2013-2018 seasons, covering team box score statistics
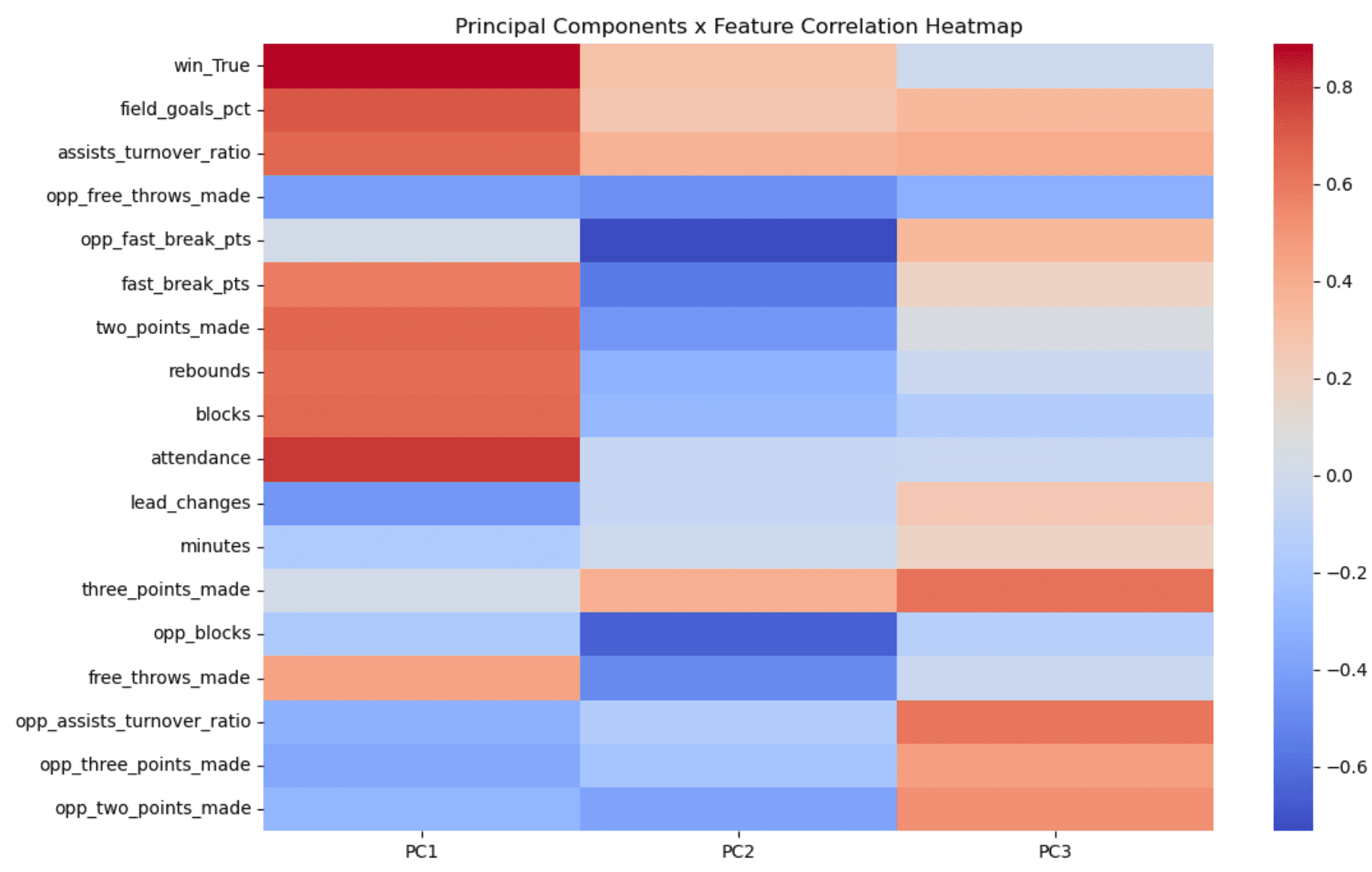
- Use of PCA to reduce data from 18 to 3 dimensions while explaining 55% of variance
- Identified what each principal component dimension means for easier interpretability
- PCA Dimension 1: positively correlated with winning statistics
- PCA Dimension 2: negatively correlated with opponents winning statistics
- PCA Dimension 3: positively correlated with both teams making threes
- K-means clustering to group teams based on playing style and performance
- PageRank analysis to rank the clusters
- Visual representation of clusters and relationships between team performance metrics
- Data cleaning and feature selection to ensure accuracy and relevance of results
Cluster Statistic Correlation Heatmaps
The images below show which stats correlate with which principal components and which principal components correlate with which clusters.

Technologies Used
- Python
- Pandas for data manipulation
- Scikit-learn for PCA and K-means clustering
- Matplotlib and Seaborn for data visualization
Impact and Results
This project identified meaningful clusters of NCAA Division I men's basketball teams based on their play styles and performance metrics. By using PCA and k-means clustering, the analysis revealed groupings of teams with similar strengths and weaknesses. These insights can help coaches and teams evaluate their own performance and strategize against opponents by understanding how they compare to other teams. Additionally, this method could be useful for sports analysts seeking to add deeper, data-driven insights into their commentary on games.
Conclusion
The combination of data science techniques and basketball analytics proved to be a powerful way to uncover new insights about team performance in NCAA basketball. Clustering teams based on statistical performance offers an advanced lens through which to evaluate teams, giving players, coaches, and analysts better tools to understand and improve the game. This study opens the door to future work on player-level analysis or applying these methods to other sports.